728x90
<서비스 디스커버리 패턴 >
서비스 디스커버리
- MSA와 같은 분산 환경에서는 Network를 통한 API 호출이 필수이다
- 다른 서비스를 호출하기 위해서는 위치 정보를 알아야 한다 - IP, Port, URI
- 전통적인 환경에서는 서버들의 위치 정보가 정적인 경우가 많다
- 따라서 원격 서버의 위치 정보를 설정 파일 등으로 관리가 가능하다

- 기존 서비스에서는 Client가 다른 Service를 호출하려면, Client 내에 config 파일에서 다른 Service에 대한 정보를 정적으로 가지고 있어야 했다

- 또는 Service 앞에 Reverse Proxy 서버가 존재하여, Client가 요청을 보내면 이를 Reverse Proxy가 받아서 Service로 전달하는 방식을 사용했다
- Reverse Porxy 안에 뒷 단의 Service 들에 대한 주소 정보를 가지고 있다
- Cloud 기반의 MSA 환경에서는 모든 것이 변화한다
- 인스턴스의 개수, 인스턴스의 IP 주소 등이 항상 변화한다
- Scale out
- Fail Over
- Upgrade
- 따라서 클라이언트는 변화하는 원격 서버의 주소를 알아낼 방안이 필요하다

- 위처럼 서비스에 장애가 생기면 해당 서버는 재구축되면서 주소 정보가 바뀌게 된다
- 따라서 클라이언트는 바뀐 주소를 알아내야 한다

- 서비스 자체가 추가되면, 추가된 서버의 주소와 추가된 사실을 클라이언트가 알아내야 한다
- 전통적으로는 설정 파일에 추가해야 하지만, 그러면 추가될 때마다 배포가 다시 되어야 해서 비효율적이다
MSA에서 서비스 디스커버리의 중요성
- 새로운 인스턴스들이 언제든 추가되거나 제거된다
- 물리적 위치를 정적으로 저장하고 있는 방식은 비효율적이다
- 인스턴스들의 물리적 주소가 고정되어 있지 않다
- 인스턴스의 개수 조차도 일정하지 않다
- 따라서 물리적 위치가 수시로 바뀌게 되므로, 바뀔 때마다 정적 파일을 수정하는 것은 비효율적이다
- 서비스의 물리적 위치를 몰라도 호출할 수 있어야 한다
- 서비스의 논리적 이름만으로도 호출이 가능해야 한다
- 인스턴스들의 추가/삭제가 클라이언트에 영향을 미치지 않아야 한다
서비스 디스커버리 종류
- Client-Side Service Discovery
- 원격 자원을 호출하는 Client가 주소를 조회한다
- Client에서 어떤 instance를 호출할지 결정한다
- Server-Side Service Discovery
- Discovery를 담당하는 Server가 존재한다
- Client는 해당 Server만 호출한다
1. Client-Side 서비스 디스커버리
- Client가 원격 자원의 주소 정보를 조회하고 유지한다
- Client가 Service Registry로부터 서비스들의 주소 정보를 조회한다
- Client가 원격 자원들의 주소 정보 기반으로 Load Balancing을 수행한다
- Client가 자체 Load Balancing 알고리즘 코드를 보유한다

- 모든 Service들은 Service Registry로 자신의 정보(이름, IP, Port 정보)를 보내서 저장한다
- 그러면 Service Registry는 모든 서비스들에 대한 정보를 갖고 있게 된다
- Client는 Service Registry에 서비스 이름으로 서비스의 주소 정보를 호출한다
- 그럼 Service Registry에 저장된 정보를 토대로 서비스를 호출한다

- 서비스의 크기를 좀 더 키워서 보자! -> Microservice A의 크기 확대
- 각각의 서비스들은 서비스가 기동되는 시점에 자신의 정보를 Service Registry에 저장한다
- 마찬가지로 Client는 서비스를 호출할 때, Service Registry에서 정보를 불러온다
- 그러면 Microservice A에 대한 모든 정보를 불러온다
- 그리고 Client가 직접 Load Balancing을 수행하게 된다 - Client Side Load Balancing
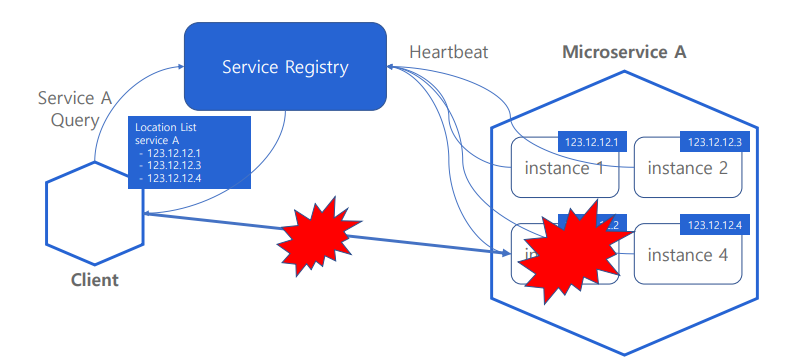
- 각 인스턴스들은 Service Registry에 주기적으로 자신이 잘 살아있다고 Heartbeat을 보낸다
- Service Registry는 Heartbeat을 받으면 이를 통해 인스턴스들의 health check를 한다
- 만약 인스턴스가 죽게 되면 Client가 해당 인스턴스를 호출할 경우 에러가 발생한다
- 그럼 Client는 Service Registry에 다시 조회를 한다
- Service Registry는 Heartbeat을 보내지 않는 장애가 발생한 인스턴스를 목록에서 제거하고 다시 Client에게 서비스 정보 목록을 보낸다
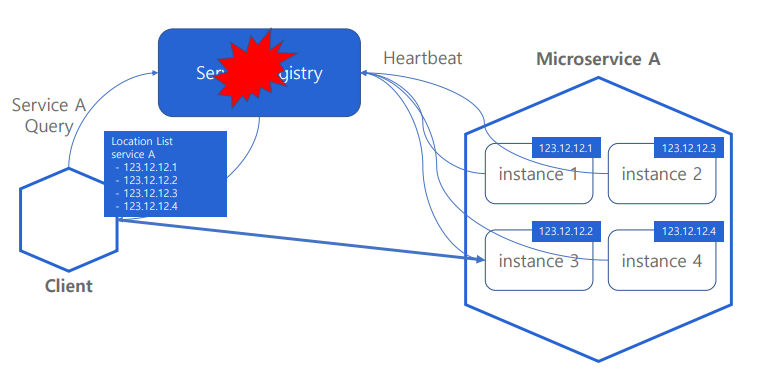
- Client가 Service Registry로 부터 조회해 온 정보를 Caching 해두는 것이 가능하다
- Service Registry에 장애가 발생한 경우, 캐싱해둔 정보를 통해 정상적인 서비스 호출이 가능하다
Client-Side 서비스 디스커버리 장/단점
- 장점
- Service Registry를 제외하고는 다른 추가 Component가 불필요하다
- Load Balancer 드을 별도로 관리하지 않아도 된다
- Client Code로 Load Balancing을 하므로 다양한 로직 추가가 가능하다
- 단점
- Client 언어와 Framework 별로 Load Balancing 로직 개발이 필수다
- Load Balancing 및 장애 내성에 대한 책임이 모두 Client에 존재한다
- 조직 통합적 관리가 어렵다
Server-Side 서비스 디스커버리
- Client는 원격 서비스 인스턴스에 대한 정보 유지를 하지 않는다
- Client는 Load Balancer를 통해 원격 서비스를 호출한다
- Load Balancer는 인스턴스 목록을 Service Registry로부터 조회한다

- LB(Load Balancer)가 추가된 형태이다
- LB는 Service Registry로부터 서비스의 정보를 가져온다
- Client가 해당 서비스를 호출하려고 하면 LB는 동적으로 가져온 정보를 통해 서비스를 연결해준다
Server-Side 서비스 디스커버리 장/단점
- 장점
- Client에 Load Balancing 등과 같은 추가적인 개발이 불필요하다
- 원격 서비스 호출에 대한 모든 기능이 LB로 추상화된다
- Kubernetes에는 기본적으로 Server-Side 서비스 디스커버리 기능이 존재한다
- 단점
- 서비스 디스커버리 기능이 있는 Load Balancer를 별도로 설치하고 관리해야 한다
Service Registry
- 서비스 정보를 등록하고 서비스 정보를 조회 가능한 Database이다
- 외부에서 호출이 가능하도록 외부에 서비스 등록 API와 서비스 조회 API 노출이 필요하다
- 항상 최신 정보를 유지해야 한다
- 고가용성을 만족해야 한다
Service Registry - 최신 정보 유지

- 서비스 인스턴스로부터 주기적으로 Heartbeat를 확인한다
- 만약 Heartbeat을 보내지 않는 인스턴스는 장애가 발생한 것으로 판단하여 목록에서 제거한다
- 문제 있는 인스턴스는 목록에서 제거함으로써 장애를 방지한다
- Client 입장에서는 Eventual Consistency를 고려해야 한다
- 물론 Heartbeat도 완벽한 실시간 정보를 제공하는 것은 아니다
- 장애 발생한 인스턴스 정보를 실시간 갱신은 어렵다
- 따라서 일시적인 장애가 발생할 수는 있지만 빠르게 복구가 가능하도록 해야 한다
Service Registry 고가용성

- Service Registry를 Active/Active 구조로 유지한다
- Service Registry 간에 정보를 공유한다
- Client에서 원격 서버 정보를 Caching하는 전략을 사용한다
- Service Registry 장애 발생시에도 원격 자원 호출이 가능하도록 한다
- Service Registry에 대한 부하를 감소시킨다
< Service Discovery의 적용>
Spring Cloud Netflix Eureka
- Netflix Eureka로부터 파생된 프로젝트
- 대규모 분산 환경에서 서비스 디스커버리를 지원한다
- Eureka Server와 Eureka Client로 구성된다
- Eureka Server가 Service Registry 역할을 한다
- Microservice, 즉 각각의 서비스들이 Eureka Client가 된다
- 서비스들이 Eureak Client가 되며 실행 시점에 Eureka Server에 자기 자신의 정보를 등록핟나
Spring Clout Netflix Eureka 기능
- 서비스 등록
- 새로운 서비스들이 자신의 정보를 등록한다
- 클라이언트의 서비스 탐색
- 클라이언트가 서비스들의 물리적인 주소를 질의한다
- 정보 공유
- 서비스 디스커버리 노드들 간에 정보를 공유한다
- 상태 모니터링
- 서비스의 각 인스턴스들은 자신들의 상태를 전송한다
Eureka 아키텍처
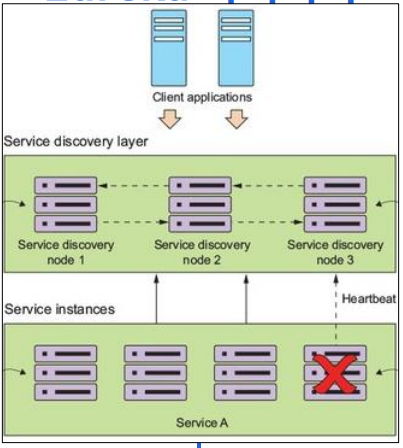

- 서비스가 생성되면 자신의 정보를 에이전트에 등록한다
- 클라이언트는 에이전트를 이용하여 서비스 위치 검색이 가능하다
- 에이전트들은 클러스터링이 가능하며, 각자의 정보를 다른 노드들에 공유한다
- 모든 서비스의 인스턴스는 에이전트에게 상태 정보(Heartbeat)를 전송한다
Eureka의 특징
- 고가용성
- 서비스의 정보를 여러 개의 노드가 공유한다
- 동시에 동작하는 Active/Active 구조로 고가용성을 만족한다
- 피어 투 피어 구조
- 서비스 디스커버리 클러스터의 모든 노드들이 서비스들의 상태를 공유한다
- 장애 내성
- 에이전트는 인스턴스의 비정상 상태를 감지하고 제거한다
- 사람의 개입 없이 가능하다
- 회복성
- 클라이언트는 서비스의 정보를 로컬에 캐시(Ribbon)
- 서비스 디스커버리가 가용하지 않을 때 로컬 캐시 정보로 서비스 접근이 가능하다
- 부하 분산
- 클라이언트의 요청을 후방 서비스들에게 분산하여 전달한다
- (추가적인 기능)
Eureka와 Ribbon

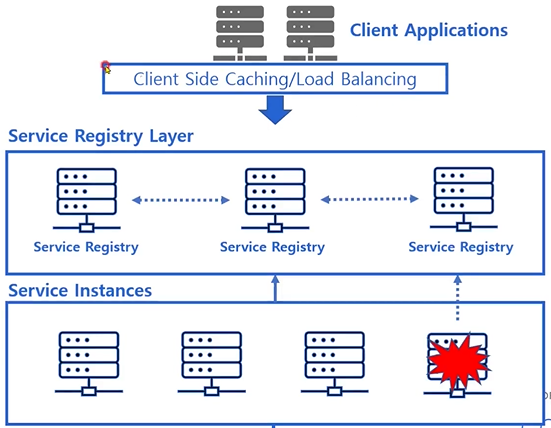
- 서비스 호출 시 마다 정보를 질의하는 방식은 비효율적이다
- 따라서 Ribbon은 에이전트로부터 받은 정보를 로컬에 캐싱한다
- 캐싱한 정보를 기반으로 서비스를 호출한다
- 주기적으로 에이전트에 다시 질의하여 캐시 정보를 갱신한다
- Ribbon은 Client-Side Load Balancing 기능도 수행한다
- Service Registry로부터 받은 서비스의 인스턴스 목록을 기반으로 Load Balancing한다
- default 알고리즘은 round robin이다
- 알고리즘은 변경 가능하다 -> Zuul Gateway 부분에서 자세히 다룰 예정!
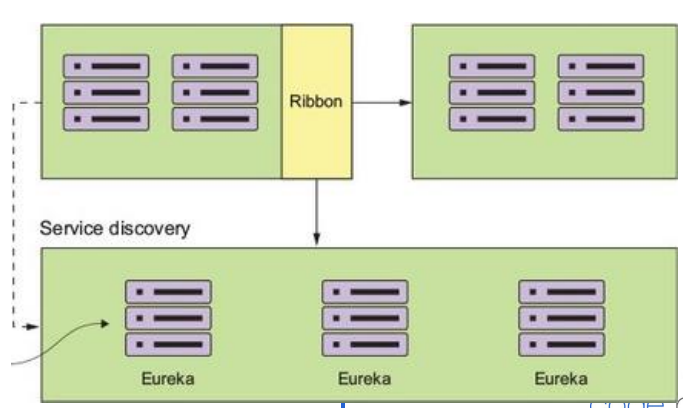
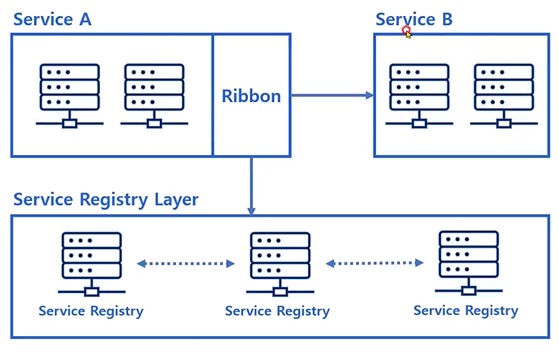
- 실제로 Service 주소 정보를 조회하는 역할을 Ribbon이 수행한다
- Service Mesh의 컴포넌트가 하는 역할과 굉장히 비슷하다
Summary
- MSA는 다양한 서비스/인스턴스들의 호출을 통한 협업이 필수다
- 원격 서버의 주소를 정적으로 저장하는 것은 비효율적이다
- Service Registry를 통해 원격 서버의 주소 정보를 동적으로 사용한다
- Spring Cloud Netlix Eureka의 Eureka Client와 Eureka Server로 Service Discovery 구현이 가능하다
728x90
'코드프레소 체험단 > MSA' 카테고리의 다른 글
| [마이크로서비스 아키텍처 : 패턴과 핵심 기술] MSA를 위한 기술 - Service Mesh와 Istio (0) | 2022.05.30 |
|---|---|
| [마이크로서비스 아키텍처 : 패턴과 핵심 기술] MSA를 위한 기술 - Container, Docker, Kubernets (0) | 2022.05.29 |
| [마이크로서비스 아키텍처 : 패턴과 핵심 기술] MSA를 위한 기술 - Spring Boot와 Spring Cloud (0) | 2022.05.28 |
| [마이크로서비스 아키텍처 : 패턴과 핵심 기술] MSA 분리 전략 - Microservice 분리 프로세스 (0) | 2022.05.27 |
| [마이크로서비스 아키텍처 : 패턴과 핵심 기술] MSA 분리 전략 - 도메인 주도 설계 (0) | 2022.05.27 |



