🖐 들어가기 전에
Cache란?

- 서비스 요청이 증가하여 DB 요청이 많아지면 DB 서버 부하가 증가하게 된다
- 이 때 메모리 캐시가 적용되면 성능 및 처리 속도가 향상된다
- 즉, 캐시 방식을 통해 DB 조회의 부하를 감소시킬 수 있게 된다
- Cache는 나중에 요청된 결과를 미리 저장해두었다가 빠르게 제공하기 위해 사용된다
- 캐시는 파레토의 법칙에 의해 모든 결과를 캐싱할 필요 없이, 서비스를 할 때 많이 사용되는 20%만 캐싱함으로써 전체적으로 효율을 끌어들일 수 있다
Cache 사용 구조
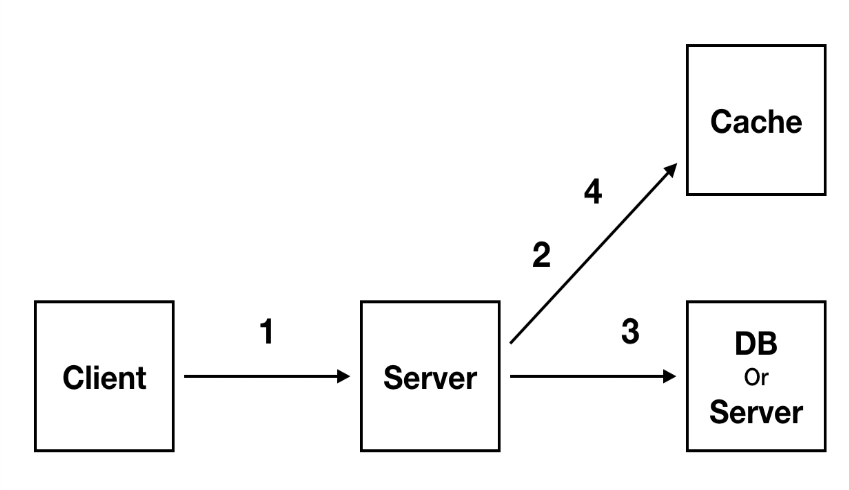
- Cache 처리의 순서는 다음과 같다
- 클라이언트로부터 요청을 받는다
- Cache와 작업을 한다
- 실제 DB와 작업한다
- 다시 Cache와 작업한다
- 클라이언트가 웹 서버에 요청을 보내면, 웹 서버는 데이터를 DB에서 가져오기 전에 캐시에 데이터가 있는지 확인하고, 있다면 바로 클라이언트에게 저장된 데이터를 반환되는데, 이를 Cache Hit라고 한다
- 반대로 캐시 서버에 데이터가 없으면 DB에 데이터를 요청하여 원하는 데이터를 조회한 후 그 데이터를 클라이언트에게 제공하는데, 이를 Cache Miss라고 한다.
- 위 flow에서 캐시를 어떻게 사용하느냐에 따라 2가지 방식으로 나뉜다
- 1. Look Aside Cache (Lazy Loading)
- 1) 캐시에 데이터 존재 유무 확인한다
- 2) 데이터가 있다면 캐시의 데이터 사용한다
- 3) 데이터가 없다면 캐시의 실제 DB 데이터 사용한다
- 4) DB에서 가져온 데이터를 캐시에 저장한다
- Look Aside Cache는 캐시를 한 번 접근하여 데이터가 있는지 판단한 후, 있다면 캐시의 데이터를 사용하고 없으면 실제 DB 또는 API를 호출한다
- 대부분의 캐시를 사용한 개발이 해당 프로세스를 따른다
- 2. Write Back
- 1) 모든 데이터를 캐시에 저장한다
- 2) 캐시의 데이터를 일정 주기마다 DB에 한꺼번에 저장한다 (배치)
- 3) DB에 저장한 데이터를 캐시에서 제거한다
- Write Back은 주로 쓰기 작업이 굉장히 많아서 INSERT 쿼리를 일일이 날리지 않고 한꺼번에 배치 처리를 하기 위해 사용한다
- DB에 갑작스럽게 쓰기 요청이 몰리더라도, write back 기반의 캐시를 사용하면 캐시 메모리에 데이터를 저장해놓고, 이후 DB 디스크에 업데이트하여 안전한 쓰기 작업을 이행할 수 있다
- DB에서 디스크를 접근하는 횟수가 줄어들기 때문에 성능 향상을 기대할 수 있지만, DB에 데이터를 저장하기 전에 캐시 서버가 죽으면 데이터가 유실된다는 문제점이 있다
💡 In-memory DB란?
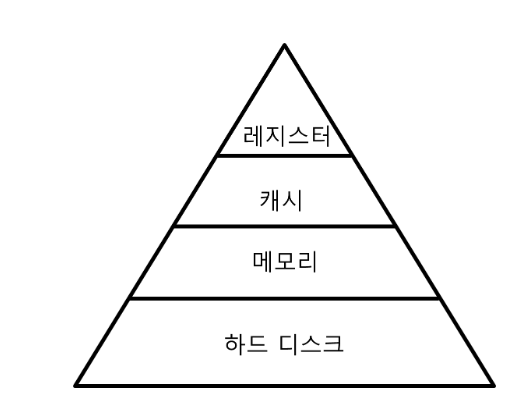
- 디스크가 아닌 주 메모리에 모든 데이터를 보유하고 있는 데이터베이스
- 디스크 검색보다 자료 접근이 훨씬 빠르다
- 데이터 양의 빠른 증가로 데이터베이스 응답 속도가 떨어지는 문제를 해결할 수 있는 대안이 되는 DB이다
- 전형적인 디스크 방식은 디스크에 저장된 데이터를 대상으로 쿼리를 수행하지만, In-Memory 방식은 메모리 상에 Index를 넣어 필요한 모든 정보를 메모리 상의 Index를 통해 빠르게 검색할 수 있다
- 그러나 이는 휘발성이기 때문에 DB 서버가 재실행되면 모든 데이터가 삭제된다
- 또한 메모리 크기가 작기 때문에 캐시용으로 사용된다
Redis

- Remote Dictionary Server의 약자로, 대용량 처리 관련 오픈소스 소프트웨어이다
- Key-Value 구조의 비정형 데이터를 저장하고 관리하기 위한 오픈소스 기반 NoSQL의 한 종류이다
- Redis는 NoSQL 중에서도 주목을 받고 있다
- 그 이유로는 데이터 저장소로 가장 빠른 메모리를 채택하였으며, 단순한 구조의 데이터 모델인 Key-Value 방식을 통한 빠른 속도를 제공한다
- 또한 캐시 및 데이터 스토어에 유리하며, 다양한 API를 지원한다
- In-Memory 기반의 Key-Value 구조 데이터 관리시스템으로써 빠르고 자유로운 데이터 처리 및 저장을 제공하기 때문에 고성능이며 캐싱, 세션 관리, 메시지 큐 등으로 다양하게 활용된다
- In-memory는 휘발성을 갖고 있어 서버를 껐다 키면 데이터가 사라지지만, Redis는 영속성을 지원하기 때문에 데이터 손실을 방지할 수 있다
- 데이터 저장소로도 활용이 될 수 있지만 redis의 특징때문에 대표적으로 Memcached처럼 RDBMS의 In-Memory Cache 솔루션으로써도 활용된다
- 즉, DB로도 사용되고 Cache로도 사용된다
- 여러 대의 서버 구성이 가능하며, 성능은 서버에 따라 다르나 초당 2만~10만 회 수행한다
Redis 특징
1) In-Memory 기반
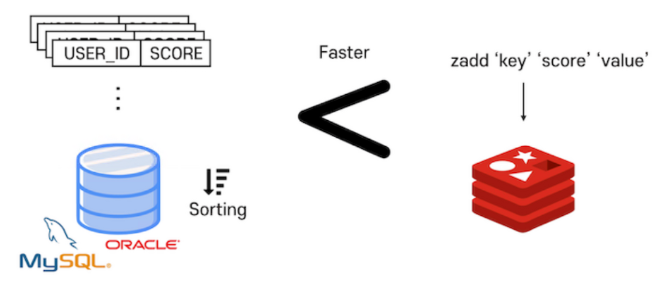
- 모든 데이터를 메모리로 불러오기 때문에 데이터를 접근할 때의 속도(읽기 속도)가 빠르다
- 즉, RDBMS가 디스크의 I/O를 이용하려 데이터를 읽어오는 작업에 비해 월등한 읽기 속도를 제공한다
- MySQL과 같은 RDBMS와 비교하면 약 10배정도 빠르다고 한다
- 또한 메모리 기반이지만 필요하다면 디스크에 백업도 가능하다 (단, 디스크에 write 비용 발생)
2) 다양한 Collection
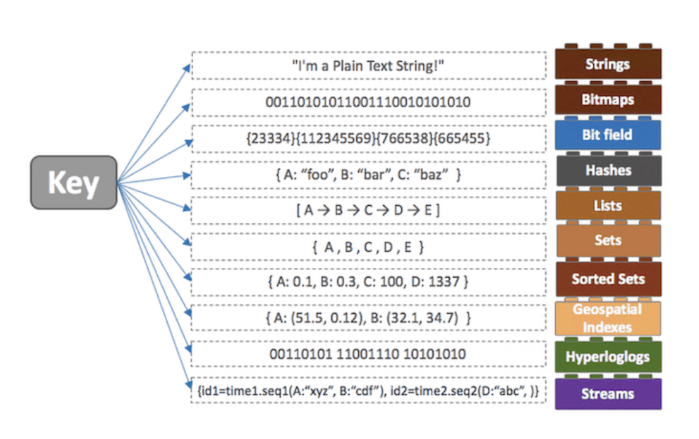
Key-Value의 구조에서 Value에 다양한 형태의 Collection을 지원한다
- String
- 일반적인 문자열로써 최대 512MB 길이까지 지원한다
- 또한 문자열뿐만 아니라 Integer와 같은 숫자와 JPEG와 같은 Binary File까지 저장할 수 있다
- List
- String의 묶음 자료구조의 형태로써 일종의 양방향 Linked List의 형태인 Quick List로 되어 있다
- 양방향 Linked List인 만큼 First와 Last에서의 삽입, 삭제가 원활하게 이뤄지고 Index 값을 이용해서 삽입, 삭제를 할 수 있다
- Set
- String의 집합으로써 중복되지 않은 값을 데이터로 갖는다
- Value 값이 중복이 되지 않고 따로 순서도 갖고 있지 않는다
- 보통 좋아요 기능이나 방문 확인 등에 사용된다
- Sorted Set
- String의 집합으로써 중복되지 않은 값을 데이터로 가지며, 가중치(score) 값을 같이 갖기 때문에 가중치에 따라 정렬이 된 데이터를 갖는다
- Value 값은 중복되지 않지만 가중치 값은 중복될 수 있다
- Hash
- 내부에 또 다른 Key-Value로 이루어진 자료구조이다
3) 싱글 Thread 기반
- 이 특징으로 인해 서버 하나에 여러 개의 서버를 띄우는 것이 가능하다
- Master-Slave 형식으로 구성이 가능하기 때문에 데이터 분실 위험을 없애준다
- 이를 통해 실시간으로 데이터를 다른 서버에 복제하여 Mastre Server가 다운되어도 Slave Server로 접속하여 바로 서비스를 계속할 수 있도록 제공한다
- 싱글 Thread를 기반하기 때문에 연산들이 atomic하고 경합(Race Condition)이 일어나지 않게 된다
- 경합이 없기 때문에 트랜잭션을 쉽게 지원할 수 있고 그에 따라 비즈니스 로직에만 집중할 수 있다
4) Redis의 데이터 보존(영속성 유지) 방법
- Redis는 Memcached와 다르게 데이터를 디스크에서 읽어서 메모리에 올릴 수 있기 때문에 서버가 내려간 후에도 데이터가 유실되지 않는다
- Redis가 영속성을 유지하는 방법으로는 Snapshot과 AOF(Append Only File)가 있다
Redis의 영속성 유지
1) Snapshot
- 메모리에 있는 데이터들을 디스크에 옮겨 담는 방식으로, 이는 2가지 방법이 존재한다
- SAVE : blocking 방식으로 순차적으로 모든 Redis의 동작을 정지시키고, 그 때의 Snapshot을 Disk에 저장한다
- BGSAVE : non-blocking 방식으로 별도의 process를 통해서 수행 당시의 snapshot을 디스크에 저장하며, non-blocking 방식이므로 Redis의 동작이 멈추지 않는다
- Snapshot 방식은 메모리의 상태를 그대로 뜬 것이기 때문에 특정 시점의 백업 및 복구에 유리하고, AOF 방식에 비해 더 빠르게 데이터를 메모리에 올릴 수 있다
- 하지만 서버가 다운되면 백업된 스냅샷 사이에 변경된 데이터들이 유실되는 단점이 있다
- 저장 파일의 확장자는 보통 .rdb 로 사용한다
2) AOF (Append Only File)
- AOF 방식은 Redis의 모든 write/update 연산 자체를 모두 log 파일의 형태로 기록하는 방법이다
- 서버가 실행되면 순차적으로 연산을 재실행하여 데이터를 복구한다
- 연산 작업이 실행될 때마다 기록하기 때문에 현재 시점까지의 로그를 남길 수 있다
- 로그 파일에 대해서 append만 수행하기 때문에 write 속도가 빠르고, 서버가 내려가도 데이터 유실이 발생하지 않는다
- 하지만 모든 연산에 대해서 로그를 남기기 때문에 데이터의 양이 매우 크고, 서버를 재시작하면 모든 연산을 다시 수행하기 때문에 restart 속도가 느리다
- 확장자는 보통 .aof 를 사용한다
💡 Redis 영속성 결론
- Snapshot과 AOF의 장점을 모아서 혼용하는 방식이 가장 바람직하다
- 주기적으로 Snapshot으로 백업을 하고, 백업 주기 사이의 간격에는 AOF 방식으로 수행하는 것이다
- 이는 서버가 restart 될 때는 Snapshot을 로드하고, 적은 양의 AOF 로그만 수행하기 때문에 restart 수행 시간이 빠르고 데이터 유실을 방지할 수 있다
Redis의 장점
- 리스트, 배열과 같은 데이터를 처리하는데 유용하다
- value 값으로 여러 데이터 형식을 지원한다 (String, List, Set, Sorted set, Hash 등)
- 따라서 다양한 방식으로 데이터를 활용할 수 있다
- 리스트형 데이터 입력과 삭제는 MySQL에 비해서 약 10배 정도 빠르다고 한다
- 메모리를 활용하면서 영속적인 데이터 보존이 가능하다
- 명령어룰 통해 명시적으로 삭제(Expires)를 설정하지 않으면 데이터가 삭제되지 않는다
- 디스크에 데이터를 기록하고 있기 때문에 Redis 메모리가 날아가도 데이터 복구가 가능하다
- Snapshot 기능을 제공하여 메모리의 내용을 해당 시점으로 복구할 수 있다
- Redis Server는 싱글 쓰레드로 수행되기 때문에 서버 하나에 여러개의 서버를 띄울 수 있다
- 위 기능을 통해 실시간으로 데이터를 다른 서버에 복제하여 한 서버가 다운되어도 실시간으로 다른 서버에서 바로 서비스를 계속할 수 있다
- Memcached보다 다양한 API를 지원한다
- 다양한 API를 지원하기 때문에 Memcached로 동작할 때보다 빠르게 작업이 가능하게 된다
Redis 단점
- 메모리 파편화가 발생하기 쉽다
- 메모리를 2배로 사용한다
- Redis는 싱글 쓰레드이기 때문에 snapshot을 뜰 때 자식 프로세스를 하나 만든 후, 새로 변경된 메모리 페이지를 복사해서 사용한다
- Redis는 copy-on-write 방식을 사용한다
- 보통 Redis를 사용할 때는 데이터 변경이 잦기 때문에 메모리 크기만큼 자식 프로세스가 복사하게 된다
- 그래서 실제로 필요한 메모리 양보다 더 많은 메모리를 사용하게 된다
- 대규모 데이터에 대한 응답 속도의 불안정성
- 대규모 트래픽으로 인해 많은 데이터가 업데이트되면 Redis는 Memcached에 비해 속도가 불안정하다
- 이는 Redis와 Memcached의 메모리 할당 구조가 다르기 때문에 발생하는 현상이다
- Redis는 jemalloc을 사용하기 떄문에 매번 malloc과 free를 통해 메모리 할당이 이뤄진다
- 반면 Memcached는 slab 할당자를 이용하여 내부적으로는 메모리 재할당을 하지 않고 관리하는 형태를 취한다
- 이로 인해 Redis는 메모리 파편화가 발생하여 이 할당 비용으로 인해 응답 속도가 느려지낟
- 다만 이는 극단적인 경우이고, 사실상 대규모 서비스에서도 Redis를 많이 도입하는 걸 보아 일반적인 스타트업 등에서 사용해도 무방하다고 할 수 있다
Redis의 대표적인 활용
1) Session Management
- Session을 Redis에 저장하여 서버끼리 세션을 공유하고, 서버의 재시작에도 세션이 초기화되는 것을 방지해주는 기능이다
2) Look Aside Cache
- 자주 조회되는 데이터를 Redis에 저장한 후, 재요청 시 해당 데이터가 Redis에 있는지 확인한 후 데이터를 반환해주는 Cache를 의미한다
3) Write Back
- 잦은 Write 작업(로깅 등)은 비용이 많이 들기 때문에 Write를 Redis에 모아뒀다가 배치 작업 등을 통해 한번에 RDBMS에 Write하는 작업을 의미한다
Redis 사용법
1) 로컬 환경에서 Redis 호출하기
- AWS EC2를 예시로 들면, 인스턴스에 Redis를 설치하여 인스턴스 메모리를 통해 Redis를 사용하는 방법이다
- 인스턴스의 메모리 여유가 있다면 비용적인 측면이나 사용성 측면으로 뛰어나다
2) 클라우드 서비스를 통한 외부 자원 사용하기
- 레디스 랩 등의 third-party 서비스를 사용하여 Redis를 사용하는 방법
- 이는 통신하는 웹 서버가 아무리 많아도 하나의 프레임워크 바인딩을 사용할 수 있다
- 이 경우에 Redis는 여러 웹 서버들의 공유 메모리 역할을 감당할 수 있다
🚨 Redis 사용 시 주의사항
- Redis는 강점이 뚜렷한 만큼 주의할 점도 분명하다
- Redis는 한 번 생성한 Key를 선택적으로 삭제하기 어렵다
- 특별한 조치를 하지 않는 이상 Redis의 Key는 삭제가 아닌 보관되며, 심지어 서버를 재실행하여도 상태가 유지된다
Redis Key
- Redis는 Key를 생성하는 방법에 따라 분산이 몰릴 수 있기 때문에 설계 또한 중요하다
- Key를 설계할 때에는 object-type : id 방식으로 하면 좋다 (ex. user:1000)
- 가독성이 좋도록 설계하고, 너무 길어진다면 hash의 member로 저장하는 것을 권장한다
Redis Key 삭제방법
- 일괄 삭제
- FLUSHDB 명령어를 통해 모든 키를 파괴한다
- 복구가 불가능하며 보통 개발 수준에서 사용된다
- 일정 시간 이후 삭제
- 각각의 키를 저장할 때 Set에 저장하여 특정 시간이나 조건에 따라 삭제하는 방법
- 이는 실제 삭제를 사용한다기 보단 밀어내기를 한다고 이해할 수 있다
- Set은 하나의 Key에 대해 여러번 등록을 해도 하나의 데이터만 남게된다
- 이러한 특징과 더불어 Set은교집합, 차집합, 합집합 같은 기능을 제공한다
- 두 가지 특징을 활용하여 교차되는 Key만 남기거나 뺀 연산을 적용하여 Key를 삭제할 수 있다
- 기간 만료 후 삭제
- 이는 가장 많이 사용되는 방법으로, Key를 추적할 필요 없이 쉽게 관리가 가능하다
- 이 방식을 사용할 때는 Key-Value를 SET 커맨드로 저장하여 EXPIRE 커맨드로 기간 만료 시간을 정하는 방법이다
- 또는 Redis 버전 2.0.0 이상을 사용한다면, SETEX 커맨드를 사용하면 된다
- SETEX 방법은 SET과 EXPIRE를 합친 것과 같다고 보면 된다
Redis 운영
Redis의 좋은 운영을 위해서는 메모리 관리가 중요하다
1) Redis 는 In-Memory Data Store 이기 때문에 물리적 메모리 이상을 사용하면 문제가 발생한다.
- 만약 swap 이 있다면 swap 사용할때 디스크에 접근하기 때문에 인 메모리를 사용해 성능을 높이는 레디스의 장점이 사라진다
- swap 이 없다면 oom(메모리 부족) 으로 죽을 수 있다
2) Max Memory를 설정하더라도 이보다 더 사용할 가능성이 크다.
- 1 byte 만 달라고해도 jemaloc 는 페이지 단위에 의해서 메모리를 주므로 4096 byte 를 할당한다
- 만약 여기서 4096 byte 를 더 요청하면 4097 byte 만 사용하고 있지만, 메모리는 8K 만큼 사용하게 되는 것이다
- 이런 현상을 메모리 파편화라고 한다
- 따라서 메모리 파편화가 일어나면, 레디스 사용량과 jemaloc 할당량이 달라진다
3) 큰 메모리를 사용하는 instance 하나보다는 적은 메모리를 사용하는 instance 여러 개가 안전하다.
- Redis 는 쓰기 요청이 오면 copy on write 방식으로 작동한다
- Redis 는 쓰기 작업을 하면 순간 fork 를 하여 갱신할 메모리 페이지를 복사한 후 쓰기 연산을 한다. 당연히 여기서 최대 메모리를 2배 까지 사용할 수 있다
- 읽기 작업은 copy on write 방식으로 동작하지 않는다
- 예를 들면, 24GB 한대가 2 배 사용하면 48GB 사용하지만, 8GB 3 대에서 1 대가 2 배를 사용하게 되면, 32 GB 만 사용하게 된다
🖐 메모리가 부족할 때는?
1) 메모리가 더 많은 장비로 마이그레이션 한다
2) 데이터를 줄인다
✨ 메모리를 줄이기 위한 설정
1) Hash -> HashTable을 하나 더 사용한다
2) Sorted Set -> Skilplist와 HashTable을 둘 다 사용한다
3) Set -> HashTable을 사용한다
4) O(n)관련 명령어는 주의하자
- Redis 는 Single Thread 이므로 동시에 처리할 수 있는 명령 개수는 1개이며, 단순한 get / set 명령어의 경우 초당 10만개를 처리할 수 있다고 한다
- 그러나 Redis는 Single Thread 이기 때문에 오래 걸리는 명령을 수행하면 그 뒤의 명령어들은 대기를 해야한다
- 예를 들면 만약 1개에 1초가 걸리는 작업을 한다고 가정한다면, 최악의 경우 99999 개의 명령은 1초동안 그냥 대기해야 하는 것이다. 이런건 99999개의 타임아웃이 발생할 수 있는 상황이다
대표적인 O(n) 명령어는 다음과 같다.
- KEYS - 모든 데이터 순회
- FLUSHALL, FLUSHDB – 데이터 전부 삭제
- Delete Collectsions – 큰 Collections 안의 데이터 모두 삭제
- Get All Collections – 큰 Collections 안의 데이터 모두 조회
KEY 는 어떻게 대체할까?
- scan 명령을 사용하는 것으로 하나의 긴 명령을 짧은 여러 번의 명령으로 바꿀 수 있다
- 짧은 명령 사에이 read 몇 만개가 처리될 수 있다.
Collections 의 모든 데이터를 가져와야할 때 어떻게 대체할 수 있을까?
- Collections 의 일부만 가져오거나 큰 Collections 을 작은 여러개의 Collection 으로 나눠서 저장한다
- 예를 들면, UserRanks 를 UserRank1, UserRank2, UserRank3로 나눠서 관리한다
💡 Memcached vs Redis
- Memcached란 오픈소스 분산 메모리 캐싱 시스템으로, In-Memory Cache를 지원한다
- In-Memory, Key-Value등의 특징이 Redis와 상당히 비슷하지만 약간의 차이가 존재한다
- Redis의 경우 최대 512MB의 Value를 제공하지만, Memcached 같은 경우 최대 1MB까지의 Value를 제공한다
- 또한 Value 타입에 있어서도 Redis는 String, Set 등 다양한 Collection을 지원하지만, Memcached는 bytes만을 제공한다
- 작업환경에 있어서 Redis는 싱글 Thread 기반이고, Memcached는 멀티 Thread 기반이다
- 사실상 Memcached나 Redis는 성능 차이가 크게 나지 않기 때문에 Redis로 통일해서 사용하는 것이 관리 및 확장성 측면에서 좋을 것 같다
- 메모리가 날아가면 서비스에 문제가 생길 수 있다면 redis에, 메모리가 날아가도 원본 데이터로 즉시 복구가 가능한 데이터는 Memcached에 저장하는 것을 추천
- 통신 속도를 향상시키는 것이 목적이라면 Memcached를 추천
- 서비스 특정 기능을 위한 목적으로 캐시 데이터를 사용한다면, 복구가 가능한 redis 추천
참고)
https://minkwon4.tistory.com/257
[NoSQL] Redis란
Redis란? Redis란 "REmote DIctionaty System"의 약자로써 Key-Value구조의 비정형 데이터를 저장하고 관리하기 위한 오픈 소스 기반 NoSQL의 한 종류이다. In-Memory 기반의 Key-Value 구조 데이터 관리시스템으..
minkwon4.tistory.com
[Redis] 레디스(Redis) 개념
레디스(Redis)란? 레디스(Redis)는 Remote Dictionary Server의 약자로서, 'Key-Value' ...
blog.naver.com
https://brunch.co.kr/@skykamja24/575
레디스(Redis)는 언제 어떻게 사용하는 게 좋을까
레디스를 사용해 본 적 없는 백엔드, 데이터베이스 개발자를 위해 | 레디스는 시스템 메모리를 사용하는 키-값 데이터 스토어입니다. 인메모리 상태에서 데이터를 처리함으로써 흔히 사용하는
brunch.co.kr
https://happyer16.tistory.com/entry/Redis%EB%9E%80
Redis란?
Redis란 Remote Dictionary Server의 약자이다. Redis의 특징 - 다양한 Collection 지원 Redis는 In-memory 데이터베이스이다 디스크 접근인 RDBMS 속도 << 메모리 접근인 레디스 이게 흔히 알고 있는 Redis의 특..
happyer16.tistory.com
https://velog.io/@rudwnd33/TIL-10%EC%9B%94-27%EC%9D%BC
[TIL] 10월 27일: 인메모리 DB(In-memory DB)
인메모리 DB
velog.io
https://americanopeople.tistory.com/148
[Cache]Redis vs Memcached
VS 캐시를 사용할 때, Redis와 Memcached 중 어떤걸 선택해야하는지 고민이 될 때가 있다. 그래서 실무에서 발생하던 사건들과 책과 구글에서 본 내용을 기반으로, 어떤 경우에 두 캐시가 각각 유
americanopeople.tistory.com
https://steady-coding.tistory.com/586
[데이터베이스] Redis란?
cs-study에서 스터디를 진행하고 있습니다. Cache Cache의 개념 Cache란 나중에 요청할 결과를 미리 저장해둔 후 빠르게 서비스해 주는 것을 의미한다. 즉, 미리 결과를 저장하고 나중에 요청이 오면 그
steady-coding.tistory.com
https://goodgid.github.io/Redis/
Redis 개념과 특징
Index
goodgid.github.io
https://highright96.tistory.com/47
레디스(Redis)란 무엇일까?
현재 진행하고 있는 프로젝트 BookStore 에 Redis 를 적용하기 위해 자료를 찾다가 우아한 레디스 세미나 영상을 보고 정리해보았다. Redis 란? Redis 는 다음과 같은 특징을 갖는 데이터 구조이다. 1)
highright96.tistory.com
'야미스터디 > Database' 카테고리의 다른 글
| [DB] DB View 📌 (0) | 2022.09.07 |
|---|---|
| [DB] SQL Injection 📌 (0) | 2022.08.31 |
| [DB] DDL, DML, DCL 📌 (0) | 2022.08.10 |
| [DB] RDB vs NoSQL 📌 (0) | 2022.08.04 |
| [DB] DB Index 📌 (0) | 2022.07.17 |



